Niyaz Puzhikkunnath • April 2026 • 10 min read
Nile: The Complete Data Stack for AWS
Building a data-stack from raw AWS services causes significant management overhead. In this article, we explore how this impacts your team, and how Nile eliminates this complexity and allows AI to operate safely on your data.
Data Engineering on AWS
AWS is undoubtedly the world leader in cloud and data platforms. It is highly reliable, scalable, and secure — and therefore maintains fantastic customer trust. Many of the largest companies in the world, including most of the Fortune 500, are AWS customers.
AWS offers a wide range of services, from large managed offerings to small tools. The breadth of these services is unmatched — but this breadth also creates complexity for customers, both in terms of deciding between service offerings and in terms of configuration and maintenance overhead.
Typical Data Engineering Stack on AWS
There is no single prescribed way to do data engineering on AWS. Instead, AWS offers a variety of services and tools to help with data engineering. The services are too many to enumerate here individually, but at a very high level, let us discuss how a typical team might set up a data stack:
A data engineering stack might use S3 as the data-lake, which is the base from which everything else is set up. The data format itself is not mandated by AWS so customers are free to use a variety of data formats like Parquet, Avro, or Lance. Some even use suboptimal formats like JSON, CSV, or TSV. The catalog is typically built on Glue Catalog (other popular options include Hive Metastore, Iceberg REST catalog, Unity Catalog, etc.).
The compute is generally Spark on EMR, Glue, or AWS Batch. Data pipelines themselves are of a wide variety; it would be impossible to list all the combinations here. Step functions are a common tool for workflow orchestration. Modern teams may also prefer MWAA (Managed Workflows for Apache Airflow). Redshift, which is quite expensive, is typically used as the data warehouse and for analytical queries. Teams may also use Athena over S3 for serverless analytical queries.
Some teams use Lake Formation for access control and governance. Many others use a patchwork of IAM policies to stitch up all the permissions required. Standard tools like CloudWatch are used for monitoring and debugging purposes.
To be clear, the services discussed above represent only a fraction of what's required for a complete data engineering stack on AWS. There are so many tools to be used to complete this picture that teams use dozens of services without even realizing how much their systems have grown in complexity.
By the way, this is just the engineering stack. We haven't even talked about the semantic layer on top, which will require even more services.


The Gaps in AWS Tooling
After speaking with 50+ data engineers using AWS for their data stack, it is clear that teams feel significant complexity when using AWS for data engineering. The complexity comes from the gaps in AWS offerings. Some of these are fundamental deficiencies in individual AWS services. Some other features are actually supported in AWS but developers don't use them properly — either because they are too hard to get right, or too obscure.
- •No Data Versioning: AWS does not support end-to-end versioning as a first-class feature. You can simulate versioning using metadata or using layers like Iceberg but it is still not complete because it gives you versioning only for the given dataset. If you have to track lineage-level versions (across parent-child datasets), you are on your own.
- •ETL Versions Not Connected to Data Versions: Let's say you use Glue for ETL. Glue scripts can be versioned, but they are not really tied to the data versions. If you ever have to debug or rollback, all of this will need to be done manually.
- •No First-Class Support for Lineage: On AWS, lineage is extra work. If you want to know exactly where the data came from, where it's going, where it's used, or how it was transformed, you need to manually keep track of all of it! If you want to know what downstream datasets store data from a particular column in your current dataset (a common audit and compliance use-case), you will have to do the manual work to figure it out.
- •No Support for Rollbacks: Due to the lack of first-class versioning across data and ETL, AWS does not natively support rollbacks across the data-lake. When things go wrong, you are on your own.
- •No Enforced Standards: Best practices and standards are not enforced in AWS data pipelines because AWS is not opinionated in any way. It just gives you all the primitive tools and lets you set things up however you'd like. Data engineers generally have a really good understanding of the best practices, and would like these standards applied uniformly on their pipelines.
The Real Cost of All the Complexity
There are some real downsides to trying to set up all layers of the data stack on your own:
- •Management Nightmare: If you list out the services that you need to manage for a fully functioning data engineering stack on AWS, you will end up using 40+ services, each requiring its own expertise and configuration. With this complexity, whenever new pipelines are created, there is a big chance that they are created slightly differently every time.
- •Orchestration and Config Sprawl: With dozens of AWS services to configure correctly and connect with each other, engineering teams are tasked with the complex orchestration of these services. Often, this orchestration is brittle and ad-hoc. There is also so much configuration that falls between these services, including IAM permissions, workflow settings, compute management, storage management, etc., that it is not easy for a single person or even teams to have expertise in all of the configs that they need to know to manage their workflows.
- •Inefficient Debugging and Rollbacks: Due to their brittle setup, workflows can easily fail due to configuration, transient, or even data problems. AWS does not provide an easy way to rollback things to the way they were in case of issues. This is also exacerbated by data issues — such as unexpected schema changes — that can cause pipeline failures. It is common for large teams to spend several days debugging data corruption or to try and rollback bad data. Rollbacks need to be carefully orchestrated because of data interdependencies. When upstreams have bad data, the rollback needs to be done in multiple layers downstream and that needs to be carefully hand-managed.
- •Inability to Use AI: You might notice a lot of pushback in data engineering communities about the usage of AI. This is because data does not have native versioning, branching, or rollbacks. One of the reasons why software developers use AI without hesitation is because they can use git to roll back if the AI does something wrong in the code.
All the issues we discussed above point to a fundamental issue: AWS provides the building blocks, but does not assemble them for you. What data teams actually need is a unified platform that manages the full stack for them. This is exactly where Nile comes in.
Nile Solves Data Engineering on AWS
Nile gives you a complete data-stack so that you don't have to build or manage any parts of it. It is a fully managed data-engineering stack, with an intelligent agentic layer on top.
Nile was built by ex-Amazon software and data engineers. We have deep expertise in running Amazon's own data-lake, which is one of the largest data-lakes in the world. We have experienced a lot of the pains around managing data stacks firsthand.
Our support for AWS is first-class. Nile sits on top of all your reliable AWS services, and manages all of your data-engineering for you. This means that you don't have to deal with all the 40+ services in AWS that we manage for you. Nile takes care of all of it transparently for you. You don't have to use multiple data stacks, stitching them together to get your data engineering done. We do data engineering end-to-end from ingestion to analytics. You just interact with Nile either using our UI or using our AI and you can get all of your data-engineering done in one intuitive platform, while getting the best-in-class data pipelines and analytical intelligence.


Here are some benefits of using Nile on AWS:
Git for Your Data-Lake
Nile versions your data, ETL, and schema — linked together. Nile knows exactly which data came into which dataset in what job, and the full lineage of all the jobs that were responsible for the final dataset.
Nile also provides branching support on your data-lake, which means that you can create zero-cost, zero-copy branches of your data-lake. Experiment with your schema and ETL changes, make sure everything works and then promote changes to production once you are confident.
Nile, built on top of standards like Apache Iceberg, gives you point-in-time recovery, and job-level rollbacks. You can undo a specific run to a specific point in time. You can also choose to cascade the rollbacks to all the dependent datasets so that the whole data-lake stays in a consistent state. The same is supported for backfill operations as well. Nile can do cascading rollbacks across your data-lake in a few seconds, saving you days of manual data cleanup.
Lineage Out of the Box
Nile keeps track of all the datasets, ETL and job runs automatically, and the data flows are fully mapped. We can give you column-level lineage too, which means that you know exactly where each column came from and what transformations were applied to it throughout your data-lake. This gives an immense amount of debugging and analytical context for AI agents to work on top of. In addition, you get complete impact analysis before making any changes. We believe that our lineage metadata is richer than any other data engineering product.
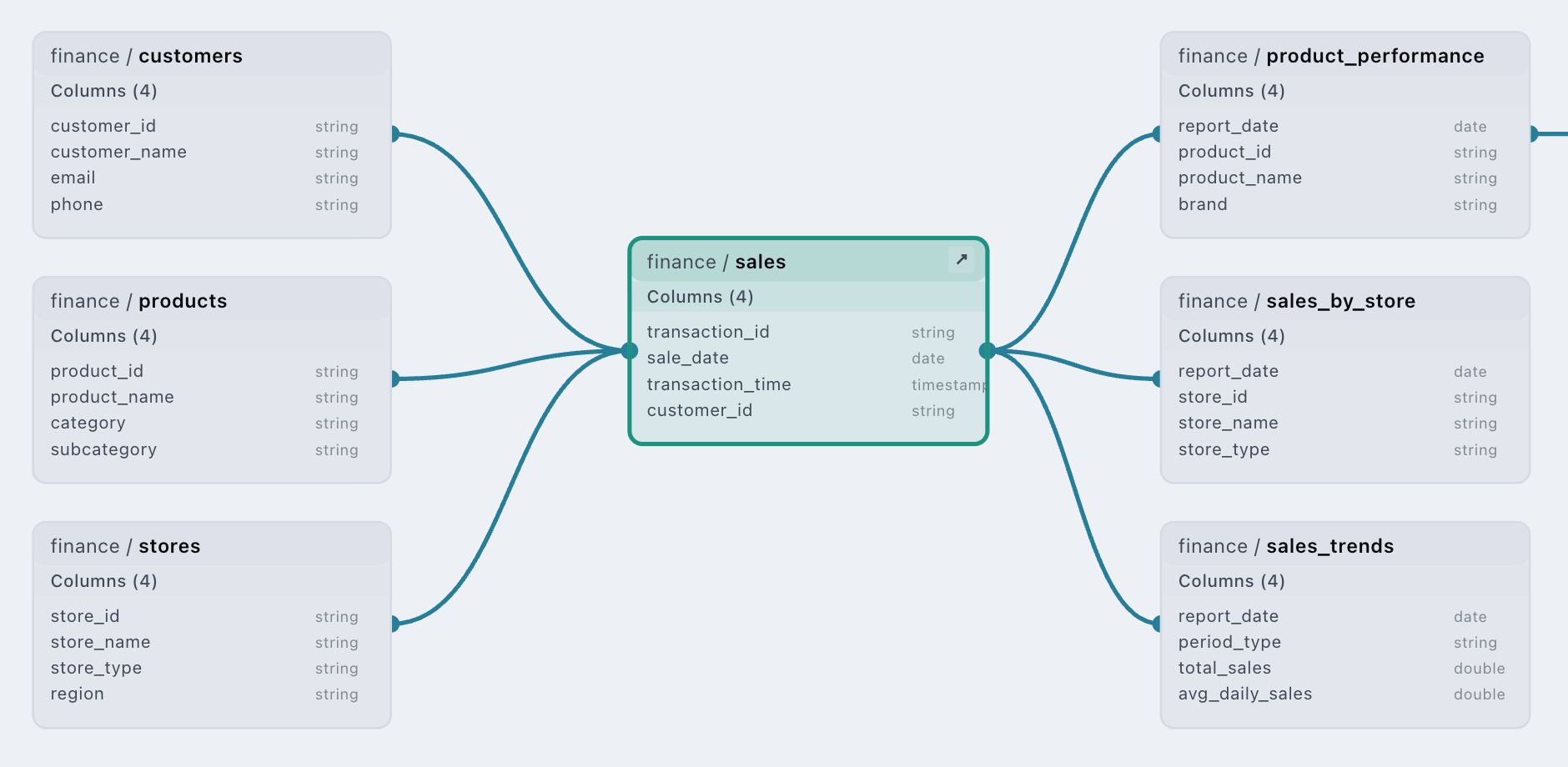
Managed Storage and Compute
Nile manages your storage for you. This means that you do not need to worry about data formats, paths, and configuration. Nile internally uses Apache Iceberg, which means Nile has zero lock-in by design and has excellent interoperability — you can connect any query engine or analytical platform to the data and seamlessly work across any of the tools that you already use.
In addition to dataset storage, Nile transparently manages the versions of your data, ETL and schema. There is no user effort required to enable any of this.
Nile completely manages your compute as well. With Nile, you don't have to specify what kind of compute is being used, how much of it to provision, etc. Simply write your ETL and Nile figures out where and how to run it so that you get optimal performance and cost.
AI That Deeply Understands Your Data
With all the context that Nile has — including the job-level lineage, ETL, and the schema — Nile can answer your analytical questions better than any other AI can. Nile has deep analytical agents that can research your data for you.
With Nile, users do not have to provide any context for their questions. You can ask a question like, "What would be the business impact of reducing my onboarding time by 30%?", and Nile will know exactly what tables to look at, what query to write, and what exactly to analyze in your data to find the right answer. Nile's answers are always rooted in your data and reproducible — grounded in the actual SQL queries run against your datasets.
World-Class Pipelines
Every time you create a pipeline or a table, Nile follows the best practices by default — no manual configuration required. Standards are baked in from day one. Your team can ship faster with significantly less operational overhead.
This means that your data teams can truly work on the real data and semantic layer rather than trying to plumb together various AWS services and configuring them to precision. Creating a new table and its ETL pipeline in Nile takes just seconds, not hours — and you can do all that by just asking the AI agent. Even better, it is done exactly the same way every time. Nile has the right primitives to do all of your data engineering, with the best practices, in an extremely repeatable and robust manner.
Pipeline creation, ETL management, versioning, scheduling — all of it is taken care of for you. Just ask, and you shall receive.
Infrastructure on Autopilot
Since Nile takes care of the management of your data pipeline, here are some things that you can stop worrying about:
- •Storage layout and optimization
- •Storage costs and snapshot expiration
- •Schema evolution, versioning, and rollbacks
- •Infra cost optimization and SLA management
- •Debugging and fine tuning your DAGs
In addition, Nile's AI agent can take care of any data engineering tasks without manual work from you.
Built for the Agentic Future
After deep discovery, we feel strongly that for AI agents to safely operate on data, we need native versioning, branching, and rollback capabilities. Nile was built from the ground up for this. Nile builds on core data engineering primitives; hence, Nile's AI layer can safely work on your data and you can — with full confidence — let it create pipelines and manage your data. Think of our data primitives like tools in Claude Code or Codex — similar to how tools make AI deterministic on coding tasks, Nile's primitives allow it to safely and deterministically operate on your data pipelines.
Nile makes it dramatically easier for AI to safely operate on a production data engineering stack.
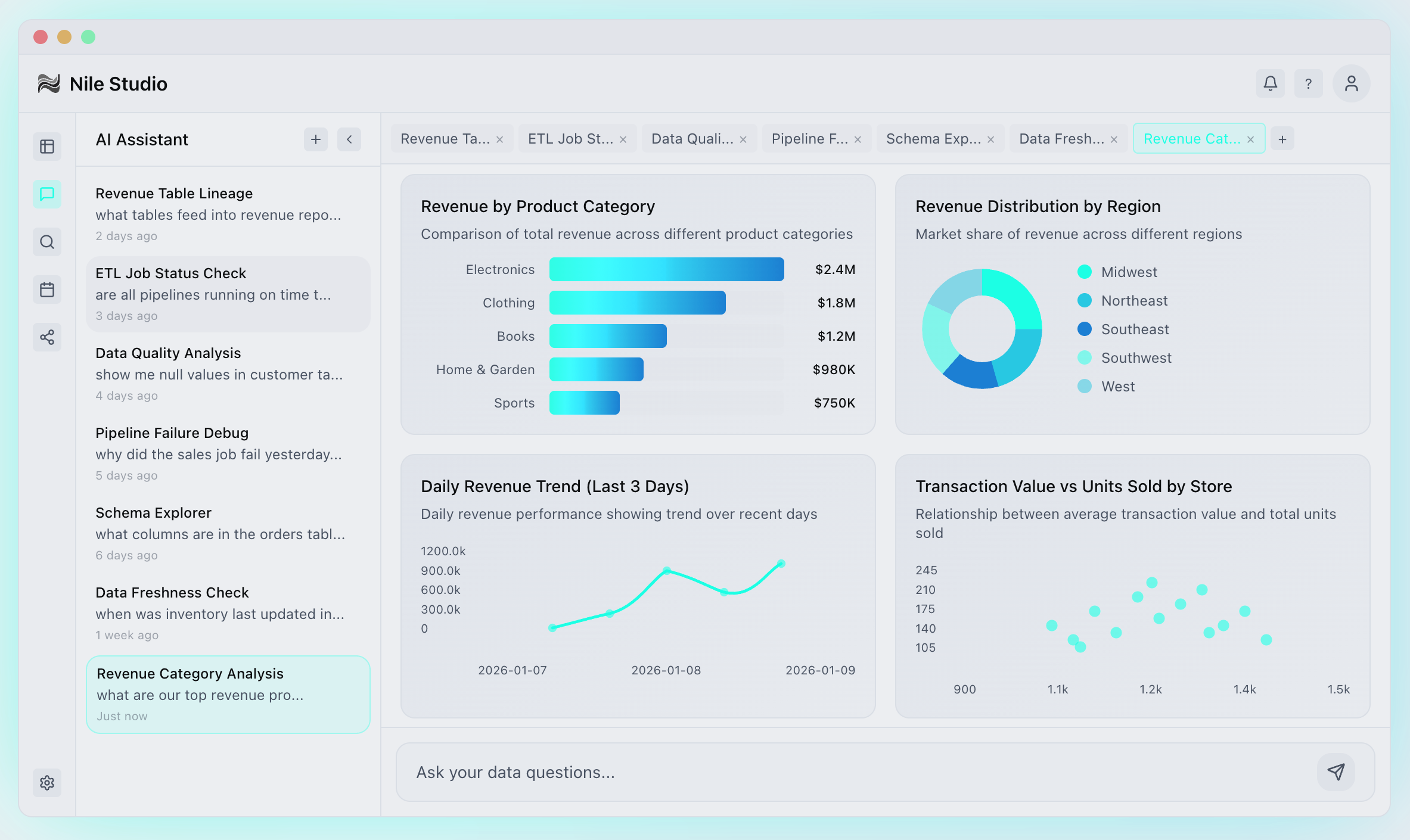
Rich context from job-level lineage, ETL, schema, and even your data allows Nile to provide high quality analytics. In addition, our agent harnesses were fine-tuned to carefully evaluate all context before they actually give you thoughtful and precise answers to your analytical questions. For your business questions, you don't have to write SQL by hand anymore. Just ask Nile, get your answers, and read through the reasoning, SQL queries, and more — so that your data engineers can verify that the answers are right.
Closing Thoughts
Nile's promise is a comprehensive, easy-to-use platform which gives you a world-class data engineering stack on AWS.
Using your favorite, reliable AWS services under the hood, and open standards like Apache Iceberg, you now have a fully interoperable data engineering platform, with zero lock-in.
With Nile's AI, your data team gets to work on data and semantic layers rather than configuring and tuning AWS services all day long.
See Nile in Action
See Nile in action in our 2-minute platform demo, or book a demo with us to chat about your data.
Get Started