Macy Mody • February 2026 • 5 min read
AI Still Isn't Safe to Run on Data
AI already changed how software is built. Coding assistants like Cursor took off because they have the ability to act autonomously. Why? Software engineers have a safety net: Git. Branches make experimentation cheap, diffs make change review manageable, and rollback can happen with a single click.
Data hasn't had its moment yet because you can't safely let AI run on data.
What's the Hold Up?
Data workflows are rarely a single system. They are a patchwork of products—storage layers, ETL tools, orchestration platforms, observability systems, and more.
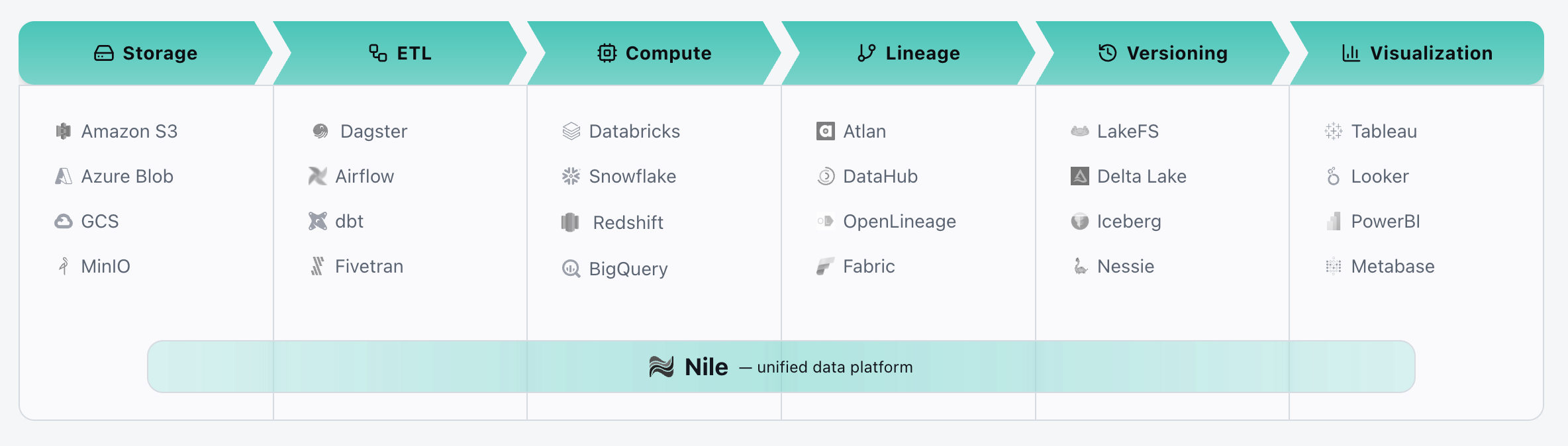

Each tool is just one piece of the data pipeline puzzle. They each store metadata differently and have their own view of truth. This leaves humans to stitch the system together with no true connection layer.
When an AI agent tries to help out in the data stack, it lacks the context it needs to act intelligently. It can suggest SQL, but it cannot see what will break downstream. It can propose a fix, but it cannot prove the fix is safe.
Disconnected Tools Make Workflows Opaque
AI needs structured context to make decisions. Today that context is scattered across various tools in the data pipeline and there's no way to view it all in one place. Dependencies live in one system. Schedules in another. Schema changes somewhere else.
As a result, AI has to guess. It may not know which upstream tables a pipeline depends on, or which downstream dashboards will break if a column changes. It cannot confidently predict the impact of a change because it has no unified view of data workflows.
Trust and Safety Are Missing
Data mistakes are expensive. One bad change can quietly corrupt weeks of reporting or trigger massive backfills. Data teams are (rightly) cautious about letting AI touch production.
Most data engineers are operating without any kind of safety net. There's often no easy way to roll back a bad change all the way through the system. There's no clean way to test in isolation, and no audit trail that tells you which exact data version produced a result.
Effectively there's no way to simply hit "undo." This makes it nearly impossible to experiment on production data, which is often necessary to build confidence that a change won't silently break everything downstream.
Why AI Coding Is Able to Work
The success of AI in software engineering wasn't just about better models. It was about better tooling.
Git gives every change a sandbox to branch, test, review, and merge. If the change is wrong, revert it. That workflow is so reliable that AI can operate without risking production.
Because of this, AI coding tools exploded in popularity. Data tools haven't had the same opportunity.
The Missing Piece: Git-Like Versioning for Data Pipelines
To make AI safe for data workflows, you need the same primitives that made Git successful:
- →A unified system
- →Versions you can trust
- →Branches for isolation
- →Reliable rollback
- →Lineage that proves what happened
That's the foundation Nile is built on. Data, ETL, and pipelines are treated as one versioned system, so AI can operate inside a controlled environment instead of guessing in production.
What Changes When the Foundation Exists
When you have Git-like versioning for data, the way AI can interact with data is very different.
1. AI Can Work in Isolated Branches
Instead of touching production data, AI can operate in zero-cost sandboxes. This means you can branch, let AI work, then validate, merge or discard changes. All of this without risking the production dataset.
2. AI Can Prove Its Answers
With full lineage and version history, AI can show exactly which data versions were used to generate an answer.
3. Mistakes Are Reversible
If AI makes a mistake or turns out to be wrong, the system can rollback to a previous version within a few seconds. This alone significantly reduces the perceived risk of letting AI execute changes on production data.
4. Humans Stay in Control
AI can propose and test, but humans approve and promote. That keeps governance intact while still accelerating velocity.
The Real Payoff for Data Teams
For data teams, the impact is tangible:
- •Fewer production incidents because changes are validated on branches first.
- •Faster iteration because experimentation is safe and reversible.
- •Lower operational burden because rollbacks and lineage are built in, not manual.
- •More trustworthy AI because it can show its work.
This is the difference between AI that "assists" and AI that can reliably operate.
A New Standard for AI in Data
If we want AI to manage data the way it manages code, the system has to be built for safety first. Versioning, isolation, lineage, and rollback aren't nice-to-haves. They're basic requirements.
Experience Git-Like Controls for Data
Try Nile Studio to see how versioning, branching, and instant rollback transform what's possible with AI in data workflows.
Try the Live Demo